
Introduction
Hebbia is building the world's most capable AI platform.
Answering the world’s hardest questions requires the world’s best information retrieval (IR) engine. At Hebbia’s core, we are an AI information retrieval lab.
In our first four years of research, we pioneered many of the state of the art approaches to IR, including semantic search and RAG. Our users' hardest queries remained unanswered. Real user questions like “What sounds like a lie in the latest Google earnings?” or “What loopholes exist in this NDA?” broke the best in class RAG systems.
In order to comprehensively answer questions that could create meaningful value for customers, we had to architect a new system from scratch.
IR is an unsolved problem, and a moving goal post, so this blog details our learnings, musings, and challenges as we continue to push the fold…
RAG Doesn’t Cut It (we would know)
In 2020, Hebbia introduced its first product, a pure semantic search system. We ingested mountains of unstructured data, building out terabyte sized corpuses of information. We iterated on various embedding techniques that all had incremental improvements to search quality, experimenting with techniques from fine-tuned BERT embeddings to custom ColBERT models leveraging the latest forms of late interaction.
The first system we put into production:
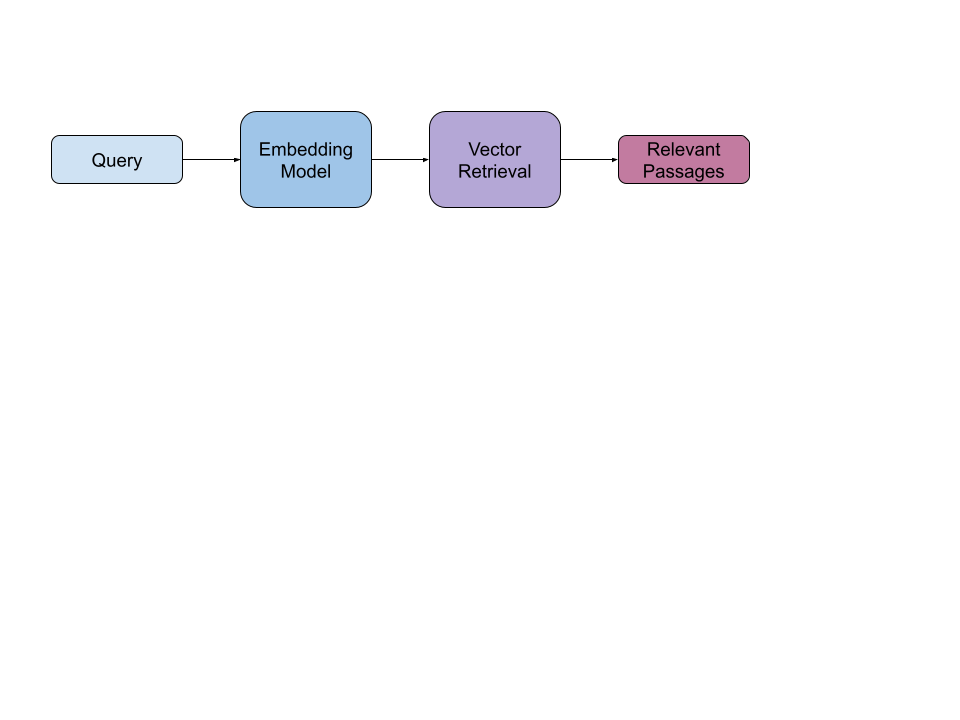
This system took a query, embedded and then retrieved relevant passages.
This system embedded “What loopholes exist in this NDA?” and found a few low relevance passages.
This system embedded “What was Pepsi’s revenue in 2022?” and found several passages about revenue, across many years and many different companies.
This system failed.
We hypothesized that initial failure was because the query vectorized by the embedding model and submitted to the vector retrieval component was sub-optimal:
- Information that conveyed document filtering was conflated with information relevant to the ideal semantic search query. For example, rarely in a 10Q filing does Pepsi make a statement that says “Pepsi’s revenue in 2022 is $X.” Rather, they may state “Revenue was $X”.
- Portions of the query lead to hits in incredibly dense portions of the vector space. For example, if you wanted to know about the growth rate for one product line, but the document contains many growth rates for many product lines - all growth rate percentages coexist in a dense portion of the vector space.
We also hypothesized that the delivered passage results were secondary to the answer the user actually desired.
In a provided query, the user was not purely looking for the collection of relevant passage results, but ideally an answer to their question. For example, a user does not want random sections of an NDA in an effort to answer “What loopholes exist in this NDA?” but rather desires critical thinking over passages that seem legally weak.
So we took a second swing and ended up building the world's first productionized RAG system:
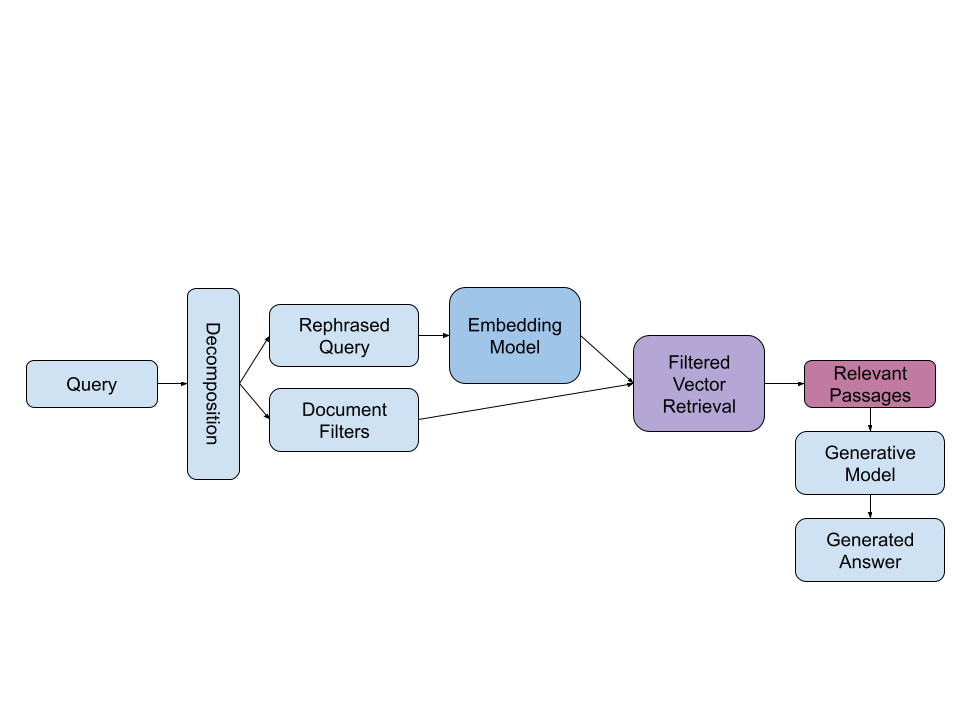
This system took a query, decomposed the user question into document filters and query phrases. We filtered, embedded and then retrieved a collection of relevant passages. Finally, a generative model was used to read these relevant passages and produce a singular answer.
This system was better but it was not game changing IR. We missed. Again.
It offered meaningful improvement for a certain class of queries, where there was clear query vs filter separation or where the relevant passages were easily found:
- “What was Pepsi’s revenue in 2022?”
- “Who are the key members of the deal team?”
However, slightly more complicated queries that required reasoning, induction or logic resulted in failures:
- “What sounds like a lie in the latest Disney earnings?”
- “What loopholes exist in this NDA?”
- “If the section says this, go to the section that it refers to and check the definition, otherwise if it says this, evaluate this other clause”
Regardless of our decomposition process or filter generation process, the embedding process struggled to appropriately encapsulate chains of thought or conditional logic. How do you produce the relevant vectors for an embedding process when you don’t know what the contents of an expected loophole looks like? How do you embed a query to find a section that you don’t know about yet?
“Traditional RAG systems conflate passage and document retrieval.”
These systems often treat the retrieval of entire documents (the atoms for question answering) equivalent to specific passages retrieval (the question answering itself). Considering them separately, document filtering queries are more often structured as information about a document rather than upon content within the document itself. As a result, a singular query process led to diminished quality for both objectives.
“RAG lacks the sophistication to answer complicated and meaningful user queries.”
When considering the queries that could be handled using RAG, significant qualitative dropoff was seen in queries that incorporated compound objectives, conditional goals and/or abstract concepts. Traditional RAG systems, which may excel at retrieving straightforward factual data, struggle to weave together multiple layers of logic. Queries with conditional goals demand that the system not only retrieve relevant information but also apply logical reasoning to evaluate hypothetical scenarios. This level of cognitive processing is challenging for RAG systems, which are primarily designed for retrieval and generation rather than complex reasoning – In other words, RAG failed on hard questions.
“RAG leaves context on the table.”
We were now left with a conundrum and opportunity - we needed to completely re-invent our core question answering competency. We needed to build a system as logical as a lawyer and as thorough as an investor.
Part 2: Paying Full Attention
RAG was failing. But, our learnings provided two new hypotheses:
Firstly, we wanted to explicitly decouple the objectives of document retrieval from document understanding. As we combed through failure cases and hundreds of user sessions, it was abundantly obvious that the conditions that users leveraged to fetch data could be better processed independently. Further, document retrieval is secondary to the need for pristine question understanding & answering. Finding the right document did not matter if you’d eventually fail to answer. And not all of our users even needed help finding the right document but they did need assistance in answering. For that reason, we decided that our primary initial focus would be on question understanding.
We approached question understanding with the goal of maximizing the application of “Full Attention”. Taking inspiration from the concept of self attention applied at a token level in transformer models, we wanted the entire question understanding exercise to be an extended version of the same theory. This meant that for compound queries, our system should enable the application of attention to the relevant document sections.
Generative models provide a powerful capability to execute upon such a strategy. Specifically, as large language models provided larger context windows, Hebbia now had an opportunity to provide a larger body of data to language models than would be possible for most embedding models. By providing larger portions of context, we then leverage the models ability to apply self attention to apply appropriate attention in complex and multi-hop queries.
Why are LLMs useful for complex questions?
- For queries that demand a nuanced understanding across multiple levels of abstraction, LLMs enable hierarchical attention strategies. At the initial layers, the model focuses on broad, overarching concepts, using attention to aggregate information that forms the foundation of the query's context. As the model progresses through deeper layers, attention is refined to target specific details, enabling a thorough exploration of the query's intricacies. This hierarchical approach is particularly effective for multi-domain queries, where reasoning must be applied across diverse knowledge areas. The multi-head attention mechanism in transformers supports this by allowing the model to attend to information from multiple perspectives simultaneously, enhancing its ability to integrate complex information.
- Further, for multi hop and compound queries, the transformer architecture’s parallel processing capability enabled better modeling of critical thinking. Unlike recurrent neural networks, which process sequences sequentially, transformers process entire sequences simultaneously, leveraging parallel computation to handle large datasets efficiently. This parallelism is achieved through the use of position-wise feed-forward networks and layer normalization, which operate independently on each token in the sequence. As a result, multiple tracks of critical thought could be processed in parallel.
Putting it all together, we deployed a multi step generative system for document level question answering.
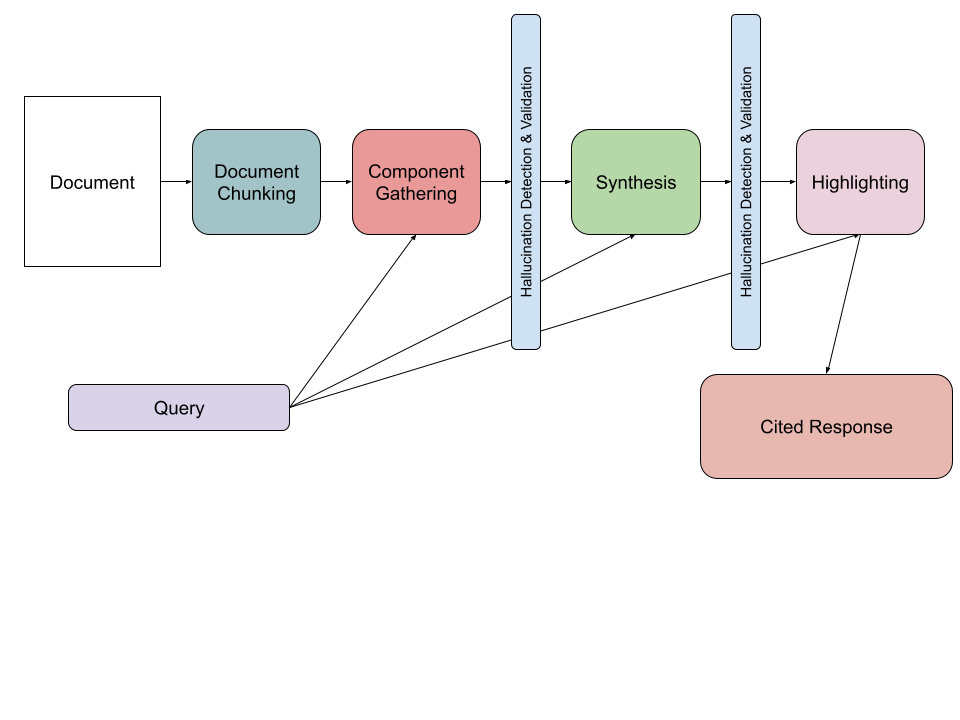
- Document Chunking: The first step involved chunking a document into contextually dense, temporally connected, and modally homogenous components that were all smaller than a context window.
- Component Gathering: Parallelizing across these chunks, our system then identifies the document components that benefit from full attention in relation to the original question.
- Synthesis: After having identified document components that require Full Attention, we run a final pass over the selected document pieces to synthesize a single comprehensive answer.
- Highlighting: Finally, we use this final response and reverse engineer the highlight worthy document text such that our users have clarity and conviction as to what parts of the document contributed to our final answer.
- Validation: Along the way through this process, our system leverages various programmatic and probabilistic measures to mitigate hallucination including leveraging token level log-likelihoods and text/character level heuristics.
Ultimately, these competencies prove more effective for understanding and answering a question rather than a distance calculation across a population of embeddings. The cosine similarity formula is a fixed calculation and as a result passage retrieval is inflexible. Inflexible passage retrieval then leads to a degraded generation operation. Generative large language models as the engine behind our passage processing process enables a form of dynamism that is a requirement for meaningful question answering.
Part 3: Scaling Full Attention
With a new and more powerful document level question answering system in tow, we now needed to scale. The individual questions were beginning to be answered, but what about broader objectives and entire workflows?
For example, when advising on the acquisition of a company, there are several complicated questions per document. But there is also an overall objective to be realized: “Diligence this company using the data found in this dataroom”... an objective, not just a question.
Serving this objective is accomplished through the composition of many different components, including agentic copiloting systems, our LLM rate limiting & coordinating service, our distributed execution engine and others. These technical innovations will be described in greater detail in upcoming blogs, but in this first blog, we want to establish our philosophy:
At each phase of the process, there is a total volume of data and a relevant subportion of data that requires the application of Full Attention. Hebbia’s goal is to design a collection of systems that, depending on the data volume for that particular scenario, are able to identify the relevant portion of data needing full attention. Two examples of this philosophy are detailed in this blog.
- Multi Document Agent: In the multi document case, we alter our single document methodology to apply self attention against a concatenated collection of attention-needy components from all of the provided documents.
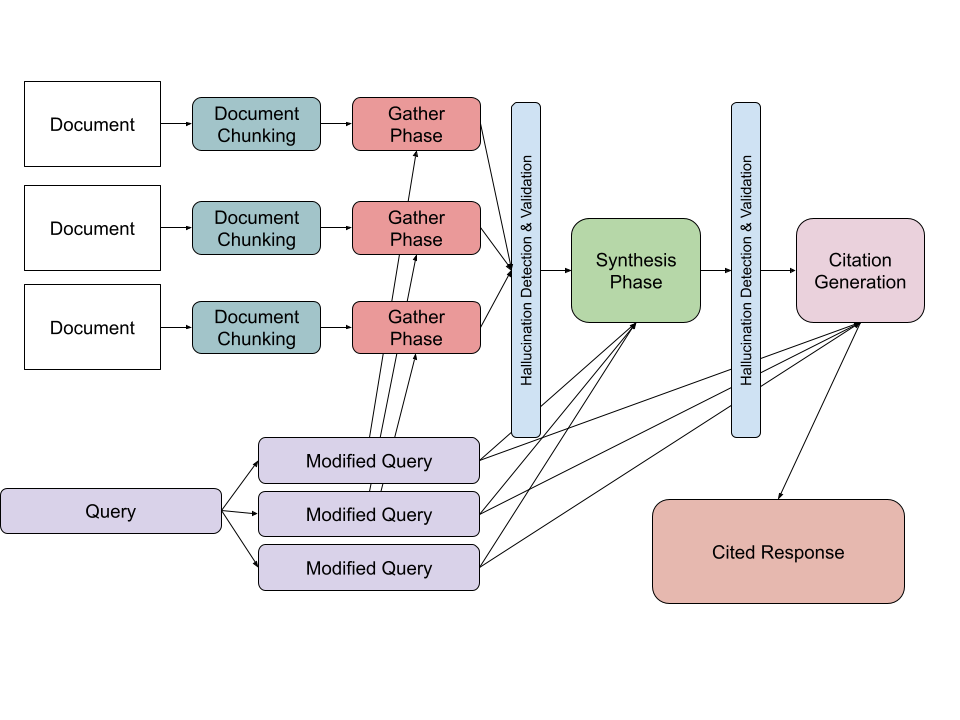
2. Matrix Agent: In the Matrix Agent case, we enable this agent to coordinate a collection of single document question answering capabilities. We then treat the generated total answer space (a Matrix) as the domain of data where we apply our full attention framework. In this variation, cell selection is the process of gathering attention to needy components, with synthesis and citation generation correspondingly helping create a single cited response.
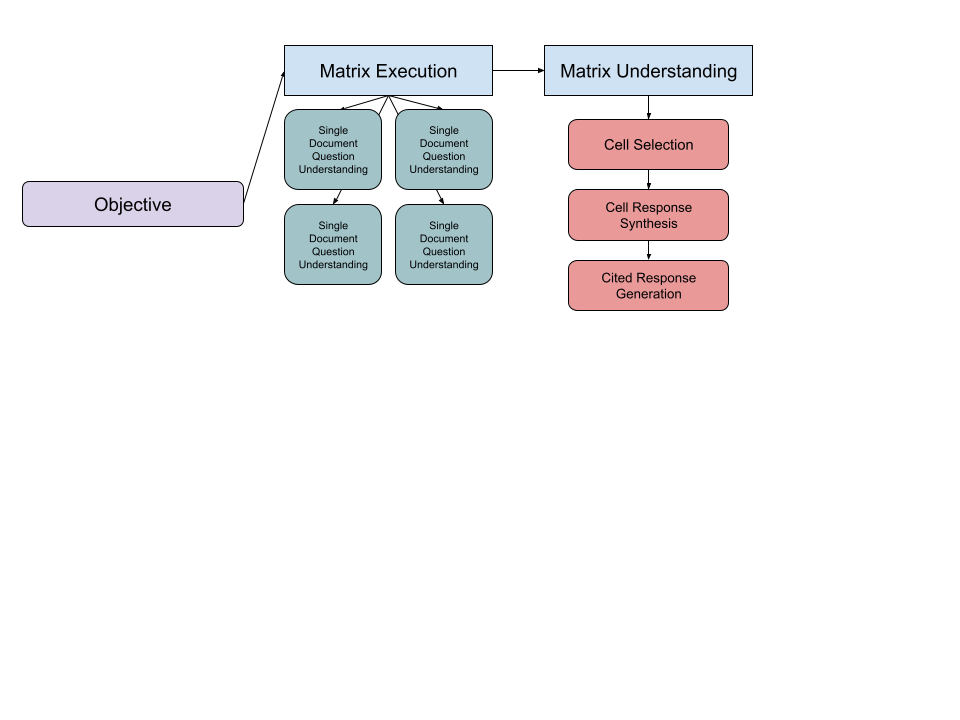
Part 4: What’s next?
Hebbia has improved staggeringly with regards to document understanding, yet document retrieval remains pinned to the same classic technologies. Today, we enable traditional document retrieval mechanisms in the Hebbia application, leveraging classical hybrid search approaches and filtering techniques, but we are grossly unsatisfied with our innovation here.
Today, document retrieval means euclidean distance calculations that generalize poorly onto new data. Document retrieval innovation today tends to be different forms of concatenation and hierarchy in an age-old vector system. We do not believe that next generation document retrieval is just going to be a reapplication of cosine similarity on slightly longer or more complicated vectors.
What do we believe? What we know is that Hebbia generates tens of thousands of document level data annotations every single day. These annotations are generated on private data largely hidden from the public eye and training sets. These annotations make for the most interesting foundation for data retrieval that we have seen in years - not just in terms of content but in terms of structure as well. We believe that vector and full text representation of documents will play a part in the solution but likely not be the entire solution. Retrieval systems should be adaptive and consider the outcomes of individual document understanding processes to formulate a better understanding of an overall document corpus.
This is the system that we are now building. A self improving, next generation information retrieval system.
If you are interested in working on problems like this, we’re hiring and can’t wait to speak with you!
Authors
Adithya Ramanathan
Lead Technical Staff
Adithya Ramanathan, Alex Flick, Lucas Haarmann
Engineering
Bowen Zhang, Sara Kemper, Ellis Geary, William Luer, Austin Shephard, Vikas Unnava, Wilson Jusuf, Ben Devore, Shirley Kabir
+ with contributions from larger Hebbia technical staff


